
可能因為我太常提到「我今天又跟ChatGPT聊了什麼什麼」,因此彷彿成為朋友間支持AI的代表人(事實上,我只是沒人可以說話),於是有些朋友遇到一些AI困擾時(例如AI一本正經胡說八道),經常會跟我抱怨。聽多了之後,我也稍稍建立了一點不太需要經過大腦的回答(明明我又不是客服),例如「都還在發展中,就謹慎使用吧。」其實,在聽了種種抱怨之後,我心中反而是懷疑一般對世界的認識方式。
➤「盡信X,不如無X」
以個人長期跑醫院的豐富資歷來說,我認為「要聽醫生的話」是一種「迷信」——如果每個醫師的看法都會一致,那就不會有「求醫一定要尋求『第二意見』」這種說法了。這並不是醫生或醫學的問題,身處在觀點與角度無比多樣的當今社會,既然最後要承受一切的也只有自己,「對所有說法半信半疑」應當是人類基本生存守則。
對我來說,與金錢、健康這類涉及生死的相關問題,沒有絕對可信的語言存在,也不會真有人替你擔負言論責任。即使具有專業能力,許多人其實跟現在的AI服務很像:假若問到的是他沒有把握的問題,他還是會硬撐回答,根本與大語言模型領域所稱的「幻覺」(Hallucination)表現一樣。
就算不是看醫師、聽取投資建議,我也無法理解有人會輕易的完全接受一家之言。所以與其跟大家說使用AI要小心,我更推薦,活在當代這種微妙世界,面對所有人、書、影片都要小心,AI並沒有比較會說謊或更具偏見。
在AI出現前,早就有「盡信書不如無書」的格言,但我不希望無書,也希望AI繼續存在。人類使用這些工具永遠需要適當的距離,在信與不信之間是一條無窮光譜。笛卡兒著名的「我思故我在」(congito, ergo sum.),後來許多學者指出完整說法是「我懷疑,因此我思、因此我在」(dubito, ergo cogito, ergo sum),感覺可以當作上述的總結。
➤失去書籍的時代
去年離開出版業時,有本名叫The Gutenberg Parenthesis(暫譯《古騰堡括弧》)的書帶給我許多安慰,它同時也提供了一種看待當代數位環境的角度。

「古騰堡括弧」這個概念最先是由專研中世紀研究的Lars Ole Sauerberg等幾位來自丹麥的教授提出並發展。後來,身兼記者、新聞學教授及暢銷書《Google會怎麼做?》作者Jeff jarvis以此為題寫了一本同名書籍,因而出圈,我也才有幸讀到。
簡單來說,「古騰堡括弧」是把印刷術發明之後的500多年時間,視為一句話中間的括弧(夾注):古騰堡發明了印刷術,是上括弧的開始,網際網路的出現則是結束的下括弧。主句其實沒變,書籍文化、印刷術像是一個插曲。從語言和認識論的角度來看,我們現在感覺到的「混亂」,其實只是「回到」中世紀口語文化的各種特徵。
當然,這並不表示括弧內的東西對我們的知識狀態沒有任何影響。這些教授們認為,500多年來因為書文化及印刷文化(或者麥克魯漢所說的「古騰堡星系」),人類文化、知識狀態和認識論都因此有了翻天覆地的改變。
其中最核心的論點是:文本(例如聖經)從此被固定、拘束在「書」上:過去抄本時代、詮釋權掌握在各個教會及其擁有的抄本。印刷術誕生後,權威轉移到書籍文字本身。除了造成詮釋權的改變,印刷術也為著作權奠定了基礎。因為文字固定了,所以誰說什麼、怎麼說都能被確定,學術上因此有了「參考書目」等文化。相對的,「抄襲」的「罪行」也才因此出現。
另一方面,說故事的方式也由口語時代的互動,轉變成線性主導。Jeff Jarvis引述《唐吉訶德》的一個場景作為例子:唐吉訶德無法忍受隨從桑丘說故事的方式,因為桑丘不是讀書人,在村裡聽故事的方式都是互動的,沒有跟聽眾合作是無法成為故事的。
唐吉訶德代表的是書本的典範,線性閱讀、開頭結尾都有一定方式(如同起承轉合),而朋友說故事的方式則像是看不到終點,也不容許你單純聽著等著語言出來。這個故事最後,因為唐吉訶德記不得羊數到第幾隻而被迫結束。(詳情可見楊絳翻譯版第20章)
➤「括弧後」時代,持續流動的思考模式
有人套用「古騰堡括弧」的概念,認為川普(Donald Trump)是「括弧後」時代的先鋒,屬於口語時代的人類,而非印刷人(可能是偷臭他沒讀書)。他沒有文字固定的概念,所以永遠不承認上一句自己剛說的話有什麼重要,永遠可以用下一句來彌補。對川普而言,所有語言都是持續流動的,跟印刷人無法對焦,聽眾總想摔筆。
這類書文化衰退的例子,在現代越來越明顯。最近我在學習一些新的AI框架或區塊鏈時,想「老派地」找一本書好好學習,但基本上是不可能的,因為沒有一本書能趕得上改變的速度。想要學習,需要追著某些大神無止盡的twitter貼文、discord上熱情的社群發言、直播。
此外,官方文件不一定寫得比一般使用者或者老玩家好,所以有心學習者勢必要改變「正文本身最重要」的閱讀習慣——能啟發你的,常常是正文下方的某則美妙留言。
本文無法深究「古騰堡括弧」這個概念,我只想從這個中世紀口語時代的角度思考:也許過去我們在括弧內過著安全、穩定的日子(即便可能是幻覺),然而從網際網路到AI,世界一點一點殘酷地把我們從括弧內拖了出來。如今我們置身的是永遠沒有終點的討論區、每一段話都有可能是鬼扯的世界。
「古騰堡括弧」學者Thomas Pettitt在麻省理工學院演講中的一段話,很能說明現狀:「文字變得失控,它們逃離了書本的拘束,變得自由,未來會有越來越多的文字繁衍出來,而且不斷移動變化,難以存在穩定的狀態……」
從網際網路的演進,我們的確看到了「括弧後」時代開展的線索:
第一階段:Wikipedia,所有人都是作者、都是編輯,搞亂「定稿」的概念,文章永遠在進行中。
目前被廣為使用的維基百科,初問世時也是備受質疑,特別是來自學院的滿臉問號。雖然現在大家都愛用,但別忘了它依然屬於不算可靠的來源,因為所有人都可以改寫某一個條目。
理論上,維基百科的辭條內容無法列為正式學術研究的參考文獻,但從它經常位在搜尋結果的前幾名推測,維基應該已經成為眾多知識的基礎入口。包括我在內,針對某個主題,我也常以「wiki上說……」開啟話題。但嚴格來說,其實這樣的開頭跟「我昨天夢到……」並無二致。
第二階段:生成式AI(LLMs、大語言模型)
我一直認為,我們身處的世界原本就沒有值得信任的對象,加上維基百科被接受應用的程度,我認為我們抵抗AI沒有太大的意義。如果沒有想要完全抵抗的話,學一下使用AI的數位素養(Literacy)可能是個不錯的選擇。
➤後書籍時代,如何使用LLMs
今年2月28日,著名的AI大神Andrej Karpathy在youtube上傳一部名為《我如何使用LLMs》(how i use llms)的影片,示範了他的AI基本教育。8天之內,點閱率已達70萬次,是很受各界認可的內容。以下摘錄影片重點,推薦大家自己去看完整影片。
1、AI基本上「只」是學舌鳥
Karpathy表示,AI本質上就是全部網路內容的破壞性壓縮(特別是上述網路第一階段的維基百科,都是訓練它的基本素材)。AI會從這些壓縮檔中取出資料,如同學舌鳥(多加了權威口吻)回答你問題。如果你要求它算數學,除非該AI額外設計可啟動特定工具來處理的功能,否則它的數學可能都會答錯,因為它的確不會算。如果答對了,會是因為訓練它的資料中有一模一樣的問題。為了解決這類問題,很多AI公司都增加工具,讓大語言模型有額外的計算功能,但這並不在它本身的能力範圍。
2、不同模型會有不同狀態,請瞭解該模型才能善用
A.每個模型基本上都有訓練資料的截止日,除非額外加上連網搜尋的功能,否則它們能夠回答的事情都只能到某一天之前。所以務必看清楚說明,或者直接問它最近資料庫更新時間。
B.可以選擇讓AI展現思路的模式(例如Gemini的Thinking、ChatGPT的進階推理),如此它會展現其推衍過程,而非直接給答案(也可以直接在提示詞要求呈現思路)。因為作為工具,我們可以只學習它的思路,這樣也許可以提供我們更可靠的幫助。
C.現在許多付費版的AI(如Gemini、ChatGPT)都提供深入研究(deep research)的功能,可以針對某個主題產生研究計畫跟報告,更重要的是,它會列出所有「出處供參考」,可以當成作研究大綱的助理,這可能是AI所做的最接近古騰堡括弧內的事情。
D.有些時候,你可以上傳其他資料,以輔助AI回答你想問的問題(除了可能需要付費外,也請顧及隱私問題)。
E.我個人加上給台灣讀者的提醒:既然deepseek是中國公司訓練的,可想而知,問它兩岸關係或者國際局勢,都是不智的選擇(除非使用的是經過調教重新訓練的「去審查版本」)。就好比若想了解歐洲文化,比起美國公司的產品,用法國Mistral的AI,講起巴黎會更頭頭是道。
3.所有AI提供的內容,都應該視為初稿(first draft)
Karpathy一再強調所有AI產出都應該視為初稿,這是當代人使用AI的最佳心態。但其實作為編輯,在我眼裡,所有人寫的都是初稿——這可能是一種職業病出發的認識論,也可能因為當代騙子實在太多。
➤透過AI協助閱讀
Karpathy表示他現在很少「單純」閱讀書籍本身,而總是找AI當書僮一起讀書。他以最近讀《國富論》為例,因為此書已經是公版權,網路上可以找到全書原文,他先把正在讀的章節內容貼給AI(影片是以Claude.ai 3.5 sonnet無付費版為例),請它針對該段作摘要(可用中文提示詞,實測沒問題)。
讀完該摘要之後,他再回頭讀原文,如此可以增加他讀書的專注力。Karpathy強調,這個方法對於閱讀自己不熟悉或者並非自己年代的書籍特別有用,讓他有勇氣接觸各種不同領域的書。
後來,他不滿意只是閱讀,更希望AI藉由互動幫助他學習《國富論》的相關知識。於是他利用Claude.ai中有點類似AI代理人的工具功能Artifacts,請AI做出記憶卡以及記憶卡練習介面。這個幾秒鐘就產生出來的小軟體,會不斷出題讓你在心中回答,再按一次則會出現正確答案,就像過去我們國中高中時使用的單詞本。背完之後,可以直接轉成測驗模式,等於作一次自我評量。
我使用以下提示詞(我改用Claude.ai 3.7 sonnet無付費),進行一樣的操作:
「請幫我針對亞當史密斯的重要生平生成20張中文的記憶卡,並利用Artifacts功能寫一個記憶卡的應用程式讓我作測試」
結果舉例如下:

最後,Andrej Karpathy又將《國富論》第三章的內容丟進Claude.ai,請它生成該文的思維導圖,以便瞭解這個章節概念的鳥瞰圖。
同樣作為應用的示範,我把這篇文章本身丟給Claude.ai,要求:「請幫我根據下方所附文件建立一個概念思維導圖」,得到的結果是:
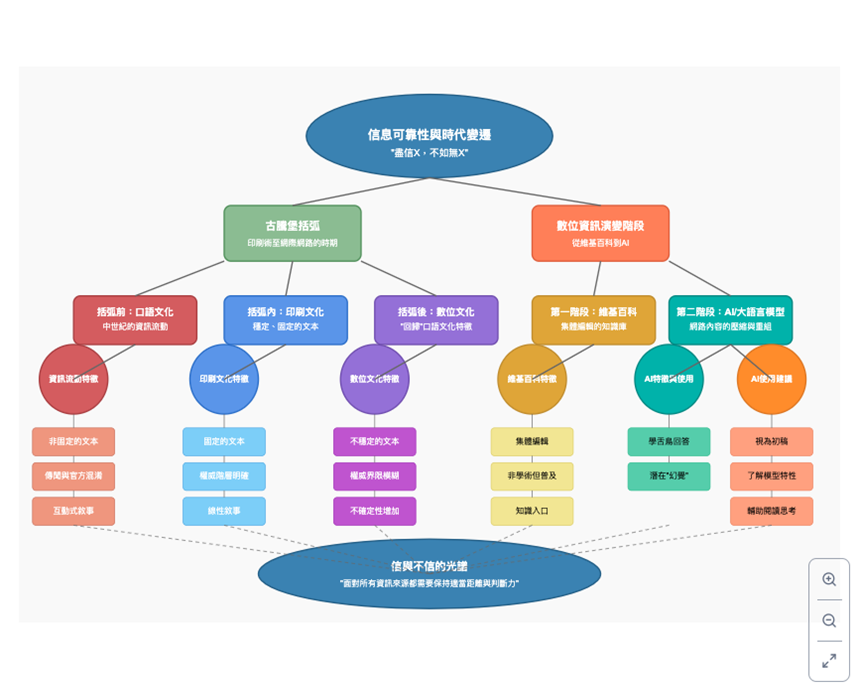
說實話,我覺得這篇文章的目的,比較像是傳統書籍讀者被迫面對現代知識學習環境的症狀緩解劑。首先當然要抱著懷疑的態度面對AI,不然我們可能會如同當年照著google地圖的指引開車開到深山去的人一樣,等到發現不對勁時已經來到懸崖邊緣。
以這樣的比喻,與其偷懶「深信」,不妨疲憊但清醒地找出這些AI「工具」擅長之處,讓AI輔助我們走一趟閱讀之旅——即便這些AI試圖奪去我們所有注意力。
最後,雖然「古騰堡括弧」可以協助我們理解當今「真理」、「知識」的狀況如何類似口語時代,但我相信AI的發展也讓我們注意到一個全新的世界。目前LLM AI最核心的能力是可以聽懂一般語言,進而跟電腦、硬體等等進行對話。近期極為熱門的vibe coding就是指對AI說你要什麼,它就可以幫你做出以前需要電腦工程師才能撰寫的程式、應用軟體出來。
這項科技的進展,讓能夠清楚思考、清晰表達這件事變得無比重要(而且可能有經濟回饋)。可以說,知識的狀態或許變得混亂了,但語言則從未如此接近行動。●


